
SEM Forests使用指南
SEM Forests使用指南
Introduction 引言
SEM 的基本流程
- SEM 是心理学和教育研究中常用的统计方法,因为它可以同时建立观测变量和潜变量之间的关系,并考虑测量误差。
- 作者引用 Kline(2023)提出的 SEM 六步流程:
- 提出基于理论的假设模型,明确潜变量和观测变量之间的预期关系;
- 检查模型是否可识别,即模型参数是否能被唯一估计;
- 选择合适的测量工具并收集数据;
- 估计模型参数,例如因子载荷,并评价模型拟合;
- 如果模型不能充分解释数据,即出现模型拟合不佳,则进行规格搜索和模型重新设定;
- 如果重新设定后的模型拟合数据,再解释和报告结果。
- 本文聚焦第 5 步:当初始模型可能遗漏协变量时,如何使用 SEM forests 辅助规格搜索。
为什么模型误设需要关注
- 作者指出,模型误设在应用 SEM 中非常普遍,因为社会科学模型往往无法包含所有相关变量和所有真实关系。
- 如果继续使用误设模型,可能导致:
- 参数估计有偏;
- 对变量关系的解释错误;
- 最终研究结论不可靠。
- 即使模型拟合指标看起来不错,也不能直接认为模型正确,因为可能存在:
- 等价模型;
- 遗漏变量;
- 拟合指标偏差。
修正指数的局限
- 规格搜索的目标,是发现模型中缺失的路径,并在保持模型简洁和理论意义的前提下改善模型拟合。
- 传统方法通常使用修正指数。修正指数会估计:如果释放某个当前固定为 0 的参数,基于卡方的模型拟合会改善多少。
- 这种方法会引导研究者逐步加入路径,形成更复杂的模型。
- 但修正指数有两个关键限制:
- 对交互效应不敏感;
- 假设初始模型包含了正确的变量集合,因此无法指出哪些模型外变量被遗漏。
SEM forests 的定位
- SEM forests 被作者定位为修正指数的补充,而不是替代全部规格搜索方法。
- 它主要解决的问题是:初始模型外是否存在有影响的协变量?
- 如果 SEM forests 识别出某些协变量,研究者可以进一步基于理论判断这些变量应如何纳入模型。
1. SEM Forests as a Tool for SEM Specification Search
SEM forests 是什么
- SEM forests 由 Brandmaier 等提出,是一种基于决策树和随机森林思想的方法。
- 它把随机森林这种非参数递归划分方法应用到 SEM 中,用于探索数据中的异质性。
- 这里的异质性指:不同子群体可能具有不同的模型参数,例如路径系数、残差等。
- SEM forests 关注的是:哪些初始模型外的协变量能够解释这种子群体差异。
为什么 SEM forests 可以用于规格搜索
- 如果某个协变量能够稳定解释不同子群体之间的模型参数差异,那么它可能是初始模型遗漏的重要变量。
- 将这些协变量纳入模型,理论上可以:
- 减少异质性;
- 提高模型预测能力;
- 改善模型拟合;
- 降低遗漏变量偏差。
- 因此,SEM forests 可以作为针对遗漏协变量的规格搜索工具。
SEM trees 与 SEM forests 的关系
- SEM forests 是在 SEM trees 基础上发展出来的。
- SEM trees 会根据模型外协变量递归划分数据,寻找最能解释模型参数差异的协变量。
- 但单棵 SEM tree 不稳定:
- 分裂可能受样本偶然因素影响;
- 某个节点的小扰动可能影响后续所有分裂;
- 结果的泛化性可能不足。
- SEM forests 通过聚合大量单棵树形成集成结果,从而降低单棵树的不稳定性。
- 如果某个协变量在许多树中反复被选中,说明它作为预测变量更稳定。
SEM Tree 是什么?
Structural Equation Model Tree,可以理解为:
用决策树的方法,帮助我们发现结构方程模型在不同人群中是否不一样。
传统 SEM 通常是在整体样本上估计一个模型,比如:
学习动机 → 学习投入 → 学业成绩
但是现实中,这个模型可能不是对所有人都一样。比如低年级学生和高年级学生、男生和女生、不同家庭背景的学生,路径系数可能不同。
SEM Tree 的作用就是:
自动找出哪些变量会把样本分成不同群体,并且这些群体中的 SEM 参数不同。
SEM Tree 的基本逻辑
可以用一句话概括:
先给定一个 SEM 模型,再让算法去找“这个模型在哪些人群中不一样”。
它的过程大致是:
- 研究者先设定一个基础 SEM 模型。
- 算法在全样本中拟合这个模型。
- 算法尝试用外部变量切分样本,比如年龄、性别、教育水平、收入等。
- 如果某个变量切分后,不同组的 SEM 参数差异明显,就保留这个切分。
- 不断重复这个过程,最后形成一棵树。
汇报时可以这样讲:
SEM Tree 不是让我们事先指定分组变量,而是让数据告诉我们:哪些变量最能解释 SEM 参数的差异。
一个简单例子
假设我们有一个 SEM 模型:
家庭社会经济地位 → 学习资源 → 学业成绩
我们手里还有一些协变量:
性别、年龄、学校类型、父母教育水平、城乡背景
SEM Tree 可能会发现:
首先,学校类型会把学生分成两类;
在公立学校学生中,父母教育水平还会进一步造成差异;
不同子群体中的路径系数并不相同。这说明:
同一个 SEM 模型在不同学生群体中可能有不同的作用机制。
SEM Forest 是什么?
SEM Forest 可以理解为:
很多棵 SEM Tree 组成的“森林”。
单独一棵 SEM Tree 很直观,但有一个问题:
它可能不太稳定。样本稍微变一点,树的结构可能就会变化。所以 SEM Forest 的做法是:
重复抽样,建立很多棵 SEM Tree,然后综合这些树的结果。
它主要不是为了画出一棵漂亮的树,而是为了回答:
哪些变量在很多棵树中都很重要?
SEM Tree 和 SEM Forest 的区别
方法 主要作用 SEM Tree 直观展示样本如何被分组 SEM Forest 更稳定地判断哪些变量重要
2. A Running Example
数据来源
- 文章使用 SISMa 项目数据作为示例。
- SISMa 项目研究德国数学相关大学专业学生在入学过渡阶段的情感变量。
- 项目特别关注:
- mathematical self-concept;
- mathematical interest。
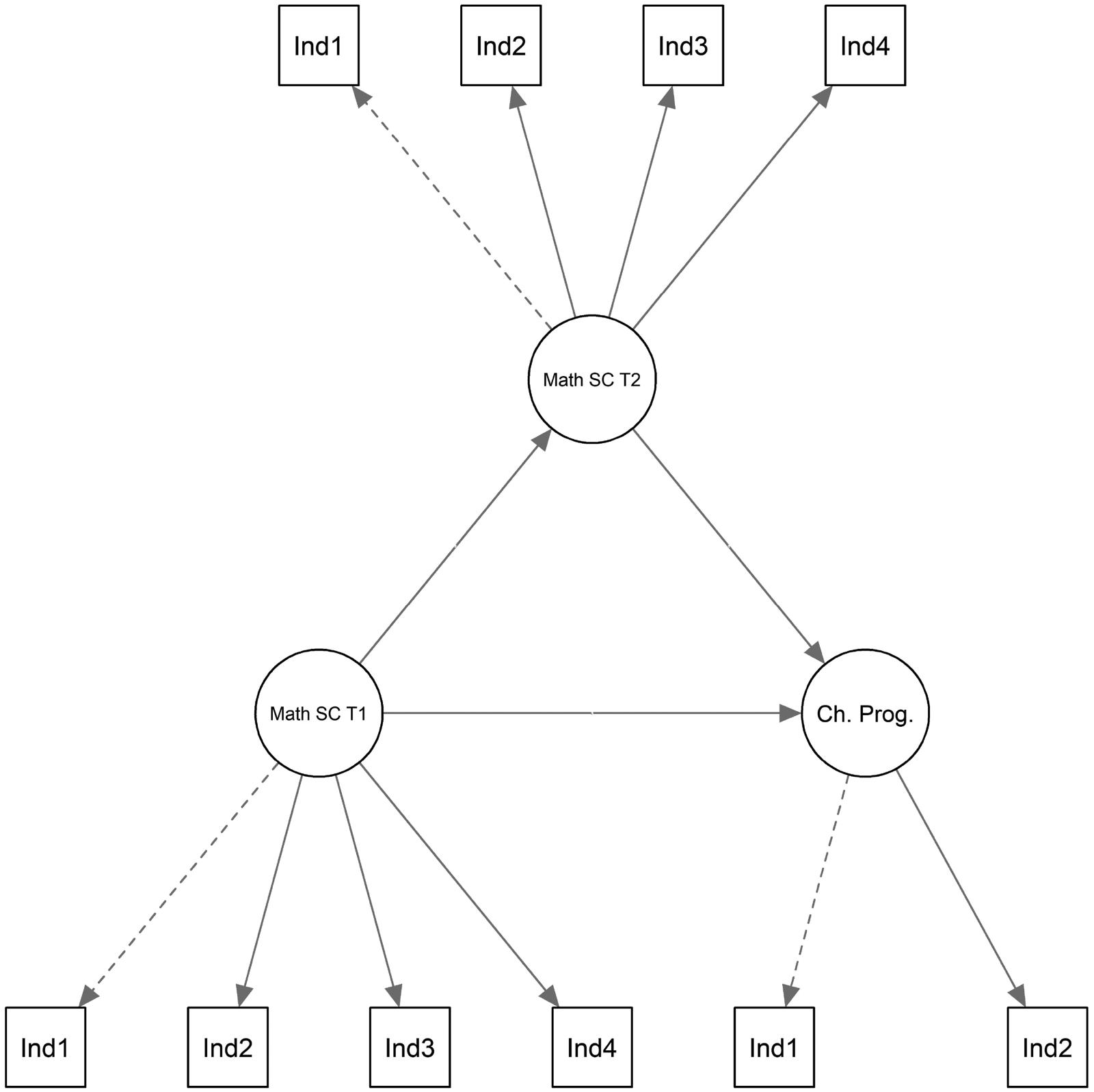
示例模型
- 作者从 SISMa 项目中选取部分变量,构建一个纵向模型。
- 模型包括:
- t1 的
general mathematical self-concept; - t2 的
general mathematical self-concept; - t2 的
tendency to change study program。
- t1 的
- 初始模型不包含协变量。
候选协变量
文章探索 8 个可能有信息量的协变量:
general interest in mathematicsschool-related interest in mathematicsuniversity-related interest in mathematicsmathematical performancegeneral school qualificationstudy programagegender
变量含义
general interest in mathematics表示一般数学兴趣。school-related interest in mathematics表示学校情境下的数学兴趣。university-related interest in mathematics表示大学情境下的数学兴趣。- 作者强调学校数学和大学数学的性质不同:学校数学更强调现象和应用,大学数学更强调公理、演绎和形式符号。
general school qualification指德国 Abitur 成绩,数值越小成绩越好。mathematical performance通过 8 道题测量学生进入大学前的数学知识。general mathematical self-concept表示个体对自己数学能力的评价。tendency to change study program由两个题项测量,反映学生未来是否有更换专业或学科的倾向。
3. A Practical Guide for Model Specification Search with SEM Forests
分析步骤
文章将 SEM forests 的规格搜索流程分为五步:
- Model specification
- SEM forests growing
- SEM forests’ variable importance analysis
- Model respecification
- Evaluation of model fit
数据结构
- 分析数据包含 202 个观测和 18 个变量。
- 其中 10 个变量是 3 个潜变量的指标。
- t1 的
general mathematical self-concept由 4 个指标测量。 - t2 的
general mathematical self-concept由 4 个指标测量。 - t2 的
tendency to change study program由 2 个指标测量。 - 剩余 8 个变量是候选协变量。
协变量的测量尺度
general interest in mathematics:0 到 3 的连续尺度。school-related interest in mathematics:0 到 3 的连续尺度。university-related interest in mathematics:0 到 3 的连续尺度。mathematical performance:0 到 1 的连续尺度。general school qualification:1 到 4 的连续尺度,数值越小成绩越好。study program:二分变量,区分 Bachelor of Mathematics 和 Mathematics Teacher Education Program。gender:二分变量。age:连续变量。
3.1. Model Specification
OpenMx 与 lavaan
semtree支持用 OpenMx 或 lavaan 指定的 SEM 模型。- OpenMx 更灵活,可以控制更多模型细节,适合高级用户;但它需要更多编程经验。
- lavaan 更直观、用户友好,更适合编程经验较少的研究者;但对复杂模型的定制能力不如 OpenMx。
- 本文使用 lavaan,是因为示例模型相对简单:只有 3 个潜变量和 10 个指标。
数据准备
- 作者强调,数据准备应根据具体数据集特点进行。
- 在本文数据中:
gender和study program被定义为因子变量;- 其他变量被定义为数值变量。
- 缺失值使用 R 包
mice处理。mice可以通过链式方程对不完整多变量数据进行插补。 - 对数值变量,作者使用预测均值匹配。
- 对分类变量,作者使用多项回归。
为什么不插补某些变量
- 作者没有对
gender、age和general school qualification进行插补。 - 理由是这些变量具有较强的质性和情境意义,标准插补算法可能无法完整恢复这些含义。
- 例如,
general school qualification的未作答可能与污名、非传统教育路径或行政异常有关。 - 这些因素不一定能被观测数据捕捉,若强行插补,可能会用算法估计掩盖真实模式。
缺失值情况与最终样本
- 各变量缺失比例从 0 到 16.83%。
- 平均缺失率为 1.87%,标准差为 3.85%。
- 除
school-related interest in mathematics外,所有变量缺失率都低于 3.5%。 school-related interest in mathematics的缺失率为 16.83%。- 插补后,最终数据集命名为
ds_imp1,包含 202 个观测。 - 作者还在 Electronic Appendix 中提供了未插补数据的补充分析,用于说明含缺失值时如何进行 SEM forests 分析。
初始模型拟合代码
sem_initial_model <- sem(model = initial_model,
data = ds_imp1,
do.fit = TRUE)
sem_initial_model <- ...:把拟合后的 lavaan 模型保存为sem_initial_model,后续生成 SEM forests 需要这个对象。sem(...):lavaan 中拟合 SEM 的函数。model = initial_model:指定初始模型语法。该模型包含潜变量及其路径关系,但不包含协变量。data = ds_imp1:指定插补后的分析数据集。do.fit = TRUE:表示实际拟合模型,估计参数并计算模型拟合。
3.2. SEM Forests Growing
为什么要生成 SEM forests
- 初始模型只设定了指标与潜变量之间的关系,以及潜变量之间的路径。
- 它没有包含 8 个候选协变量。
- 因此,下一步使用 SEM forests 检查这些协变量是否对初始模型有信息量。
至少需要设置的参数
作者建议至少指定以下参数:
- 抽样方法;
- 分裂选择方法;
- 每次分裂抽取的协变量数量;
- Bonferroni 校正;
- 分裂显著性水平;
- 最小节点样本量;
- 潜在终端节点样本量下限;
- 树的数量。
抽样方法
- SEM forests 通过从原始样本中创建随机子样本来生长 SEM trees。
semtree提供两种抽样方法:- bootstrap aggregating,即 bagging;
- subsampling。
- bagging 是有放回抽样,每个随机样本大小与原始样本相同。
- subsampling 是无放回抽样,抽取较小的随机样本。
- 作者强烈建议使用 subsampling,因为 bootstrapping 可能偏向类别更多的协变量,也可能偏向与结果变量相关更强的协变量,从而导致变量重要性有偏。
分裂选择方法
- 作者建议使用 score-guided tests。
- 与早期 SEM tree 方法(naïve 和 fair)相比,score-guided tests 的优点是:
- 协变量选择更少偏差;
- 统计功效更高;
- 计算效率更高。
- 计算效率更高的原因是:score-guided tests 只需要估计一个模型,而早期基于似然比的方法需要为每个候选分裂估计模型。
每次分裂抽取多少协变量
- 为提高树之间的多样性,SEM forests 每次分裂只随机考察一部分协变量。
- 子集大小可以用经验规则
log2(m) = c确定。 - 这里
m是协变量总数,c是每次分裂抽取的协变量数量。 - 本文共有 8 个协变量,因此
c = 3。
Bonferroni 校正
- Bonferroni 校正用于处理多重检验问题,避免 I 类错误率被人为抬高。
- 但作者认为 Bonferroni 校正过于保守,会导致树过于稀疏,并显著降低发现有信息量协变量的能力。
- Silva Díaz et al. 的模拟研究显示,在样本量 200 到 1000 的条件下,即使不使用 Bonferroni 校正,I 类错误率也接近 0。
- 因此,本文没有使用 Bonferroni 校正。
alpha、min.N 和 min.bucket
semtree默认将分裂 alpha 设为 100%。- 这有助于树充分生长,提高发现交互效应的能力,但可能增加错误识别无影响协变量的风险。
- 模拟研究显示,在样本量为 200 且 alpha = 100% 时,I 类错误率仍接近 0。
- 本文设置:
min.N = 100:少于 100 个观测的节点不再尝试分裂;min.bucket = 50:潜在终端节点至少要有 50 个观测。
- 由于本文样本量为 202,这意味着每棵树最多只有两个分裂。
- 为弥补树较浅的问题,作者使用 2000 棵树。
图 2:生成 SEM forests 的代码

# Control object to specify forests growing
control <- semforest.control()
control$num.trees <- (num.trees <- 2000)
control$sampling <- "subsample" # More accurate than bootstrapping
control$semtree.control$method <- "score" # Other methods: naive, fair
control$mtry <- 3 # log2(8), being 8 the total number of covariates
control$semtree.control$min.N <- 100
control$semtree.control$min.bucket <- 50
control$semtree.control$bonferroni <- F
control$semtree.control$alpha <- 1
print(control)
# Grow the forest
forest_dsreal <- semforest(sem_initial_model, ds_imp1, control)
control <- semforest.control():创建 SEM forest 的控制对象,用于保存森林生长参数。control$num.trees <- (num.trees <- 2000):设置生成 2000 棵树,同时把num.trees赋值为 2000。control$sampling <- "subsample":使用无放回的 subsampling。control$semtree.control$method <- "score":使用 score-guided tests 作为分裂方法。control$mtry <- 3:每次分裂随机考察 3 个协变量。control$semtree.control$min.N <- 100:节点样本量少于 100 时不继续分裂。control$semtree.control$min.bucket <- 50:每个潜在终端节点至少需要 50 个观测。control$semtree.control$bonferroni <- F:不使用 Bonferroni 校正。control$semtree.control$alpha <- 1:分裂显著性水平设为 1,即 100%。print(control):打印参数设置,检查控制对象。forest_dsreal <- semforest(sem_initial_model, ds_imp1, control):用初始 SEM、数据集和控制参数生成 SEM forest,并保存为forest_dsreal。
3.3. SEM Forests’ Variable Importance Analysis
变量重要性的含义
- 生成 SEM forest 后,可以计算变量重要性。
- 变量重要性衡量每个协变量在森林中的相对重要程度。
- SEM forests 使用的是基于置换的准确性重要性。
置换方法的逻辑
- 对某个协变量的取值进行随机置换。
- 置换相当于破坏该协变量与模型之间的真实关系。
- 如果置换后模型拟合明显下降,说明该协变量对模型重要。
- 如果置换后变化很小,说明该协变量对模型贡献有限。
数值解释
- 接近 0:协变量几乎没有预测价值,可能只是偶然进入某些树。
- 负值:置换后预测表现偶然变好,不应视为稳定重要变量。
- 正值:置换后模型表现变差,说明该协变量对模型拟合有贡献。
不建议使用 z 分数和显著性检验
- 作者不建议使用变量重要性的 z 分数,因为它依赖森林调参,跨研究不可比。
- 作者也不建议对变量重要性做显著性检验,因为检验功效同样受树数量等调参影响。
计算与展示代码
varimp_obj <- varimp(forest_dsreal)
plot(varimp_obj)
print(varimp_obj, sort.values = TRUE)
varimp_obj <- varimp(forest_dsreal):计算forest_dsreal的变量重要性,并保存结果。plot(varimp_obj):绘制变量重要性图。print(varimp_obj, sort.values = TRUE):输出变量重要性数值,并按数值排序。
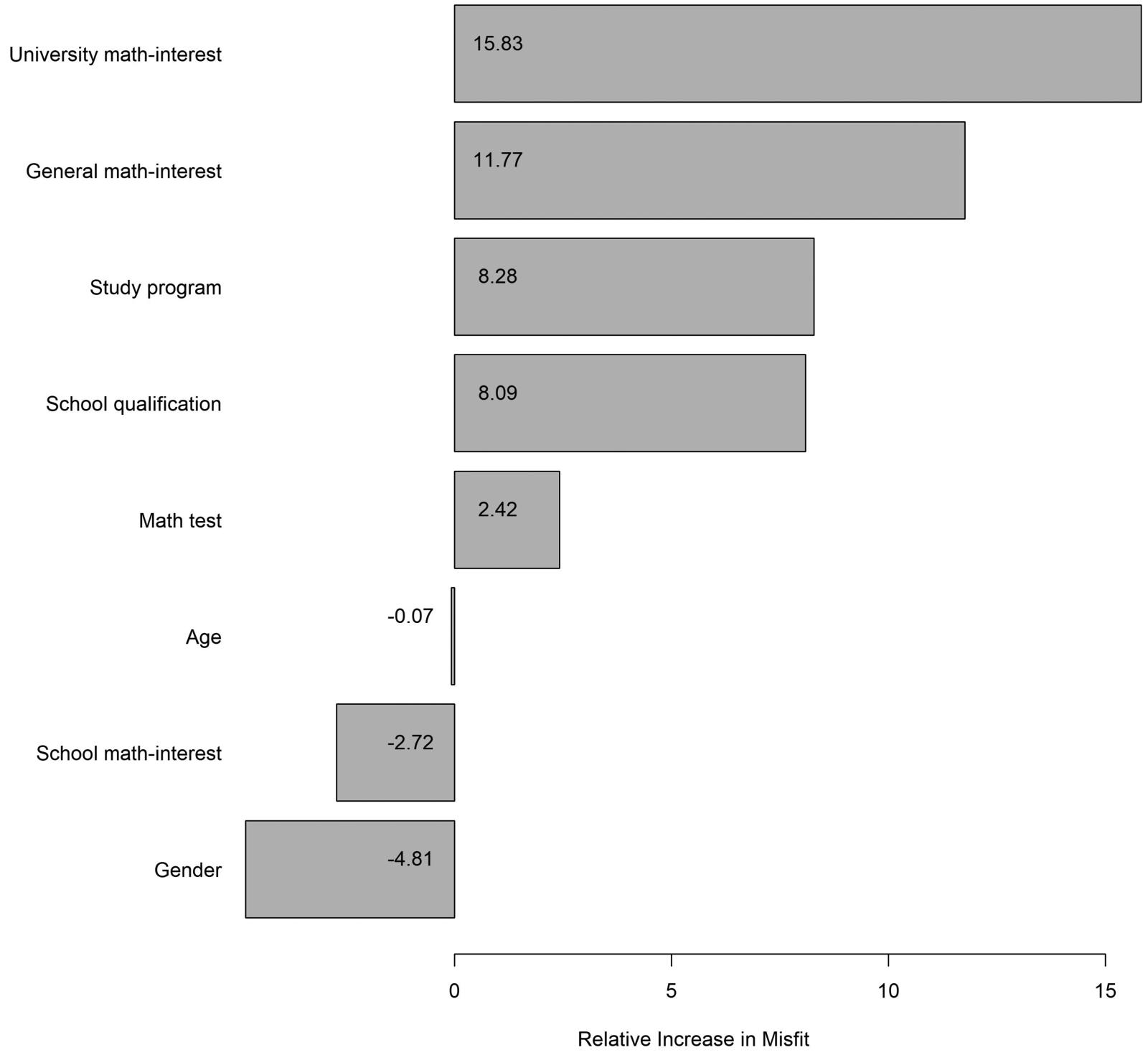
图 3 结果
- 作者没有使用固定阈值解释变量重要性,而是采用排序。
- 按 Strobl et al.的建议,应排除负值、零值或与负值范围接近的正值。
- 但按该规则会保留 8 个协变量中的 5 个,过于宽松。(我理解应该只有4个)
- 因此作者采用更保守的方式:选择变量重要性排名前 30% 的协变量。
- 最终进入后续模型的协变量是:
general interest in mathematicsuniversity-related interest in mathematics
- 作者提醒,30% 只是经验规则,不是通用统计阈值。
3.4. Model Respecification
SEM forests 不能自动决定模型结构
- SEM forests 只能告诉研究者哪些协变量可能重要。
- 它不能告诉研究者这些协变量应放在哪里,也不能决定它们应以什么形式进入模型。
- 因此,模型重新设定必须基于理论,而不能完全依赖数据驱动。
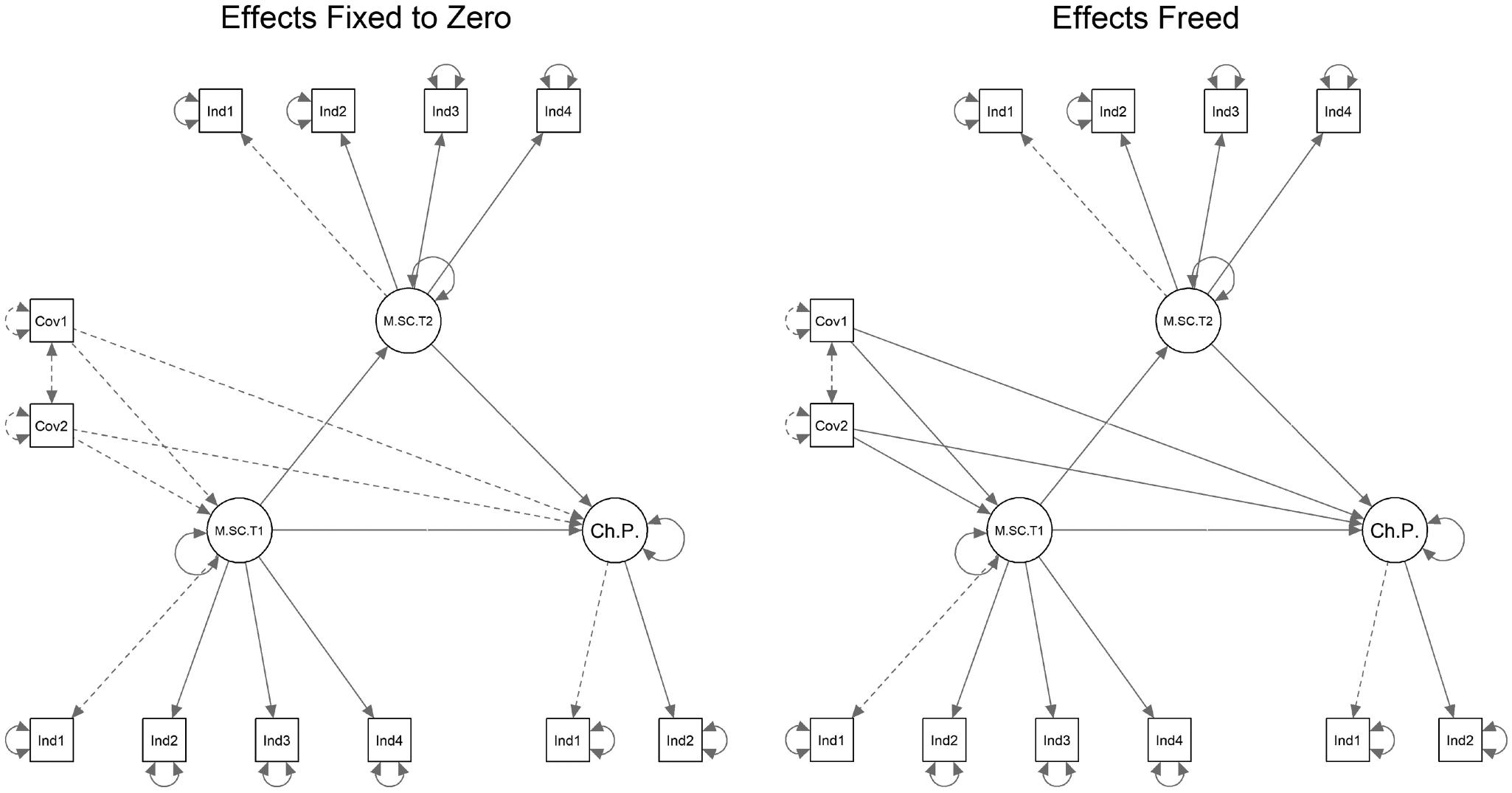
直接效应模型
- 作者将
general interest in mathematics和university-related interest in mathematics作为直接预测变量纳入模型。 - 它们被设定为预测:
general mathematical self-conceptat t1;tendency to change study program。
- 作者比较两个模型:
- 协变量直接效应固定为 0;
- 协变量直接效应自由估计。
- 如果协变量与潜变量无关,固定模型应拟合合理,自由估计模型不应明显更好。
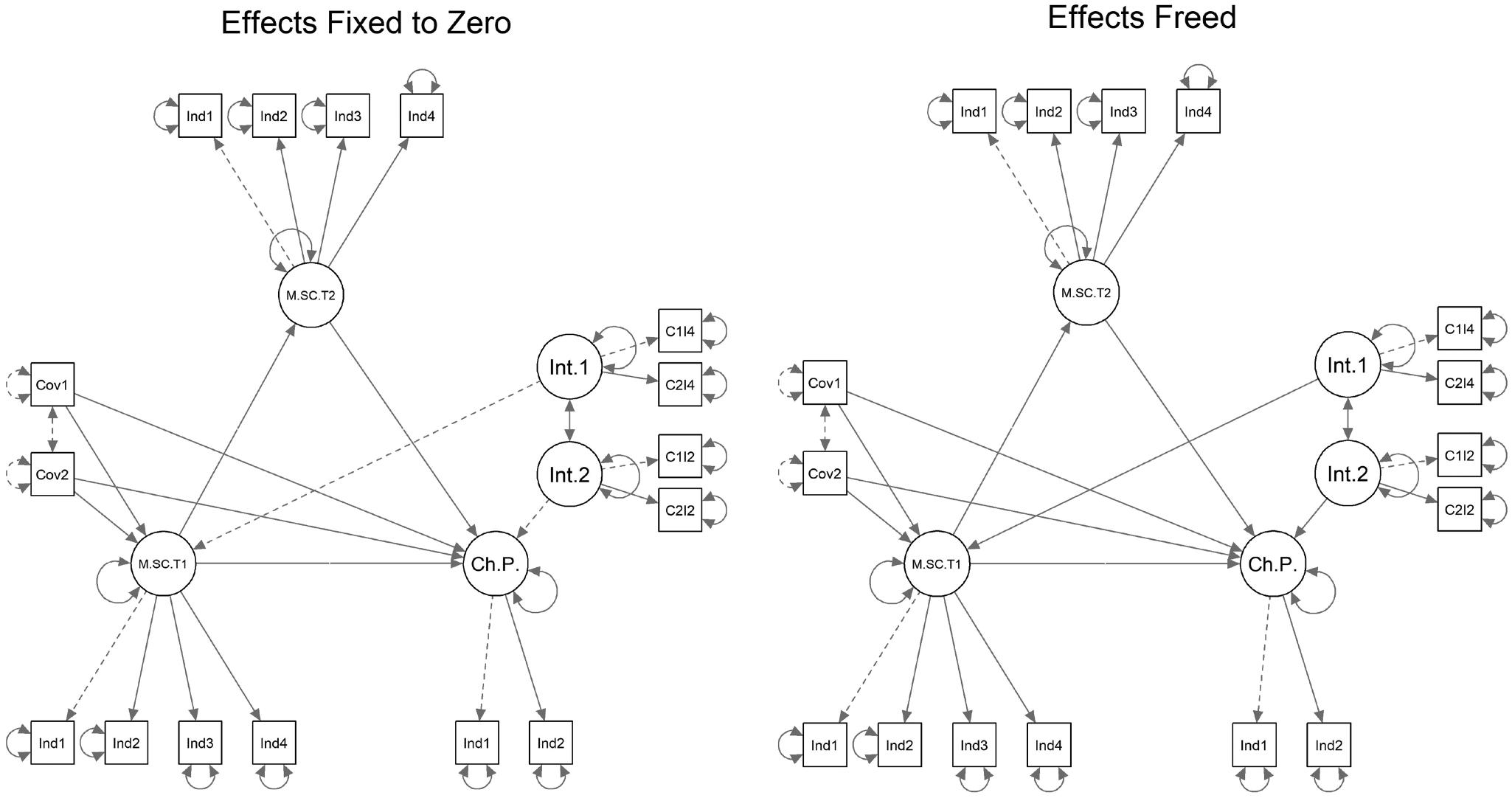
调节模型
- 作者还构建了调节模型。
- 调节指第三变量影响自变量与因变量之间关系,通常通过交互项表示。
- 在本文中,交互效应由两个识别出的协变量与相关潜变量的一个指标相乘得到。
- 使用的指标包括:
M1SAll4;M2SW2。
- 作者强调,这个调节模型主要用于说明:SEM forests 找到的协变量可以被纳入不同模型结构。
- 该模型并非基于强理论假设提出,因此实践中不能只因拟合好就采用。
双重均值中心化
- 作者使用
semTools包中的indProd()生成交互项。 - 交互项采用双重均值中心化:
- 先对参与交互的变量做均值中心化;
- 再计算乘积项;
- 再对乘积项本身中心化。
- 这样做可以降低交互项与主效应之间的多重共线性,并提高解释性。
交互项生成代码
interaction <- indProd(ds_imp1,
var1 = c("in_hs1", "in_all1"),
var2 = c("M1SAll4"),
match = F,
meanC = T,
residualC = F,
doubleMC = T)
interaction2 <- indProd(interaction,
var1 = c("in_hs1", "in_all1"),
var2 = c("M2SW2"),
match = F,
meanC = T,
residualC = F,
doubleMC = T)
interaction <- indProd(...):生成第一组乘积指标,并保存为interaction。ds_imp1:输入插补后的数据集。var1 = c("in_hs1", "in_all1"):指定两个由 SEM forests 识别出的协变量。var2 = c("M1SAll4"):指定与 t1 数学自我概念相关的指标。match = F:不使用配对方式,而是生成所有可能的乘积项。meanC = T:在生成乘积项前对主效应指标做均值中心化。residualC = F:不使用残差中心化。doubleMC = T:对生成后的乘积项再中心化,即双重均值中心化。interaction2 <- indProd(interaction, ...):在已有乘积指标的数据上继续生成第二组乘积指标。var2 = c("M2SW2"):第二组乘积指标与M2SW2相关。
3.5. Evaluation of Model Fit
比较的五个模型
- 初始模型;
- 协变量直接效应固定为 0 的模型;
- 协变量直接效应自由估计的模型;
- 协变量交互效应固定为 0 的调节模型;
- 协变量交互效应自由估计的调节模型。
表 1:模型拟合比较
| Model | CFI | RMSEA | SRMR |
|---|---|---|---|
| Initial model | .94 | .09 | .06 |
| Model with covariate direct effects fixed | .89 | .09 | .15 |
| Model with covariate direct effects free | .94 | .07 | .06 |
| Moderation model with covariates fixed | .93 | .06 | .06 |
| Moderation model with covariates free | .93 | .06 | .06 |
直接效应模型结果
- 直接效应固定模型拟合较差:CFI = .89,RMSEA = .09,SRMR = .15。
- 直接效应自由估计模型拟合可接受:CFI = .94,RMSEA = .07,SRMR = .06。
- 直接效应自由估计模型的 AIC 和 BIC 更低,说明在考虑模型复杂度后仍更优。
| Model | AIC | BIC | χ² | df | χ² difference | df difference | p value |
|---|---|---|---|---|---|---|---|
| Modified model with covariates free | 3339.0 | 3428.3 | 96.291 | 48 | |||
| Modified model with covariates fixed | 3377.7 | 3453.7 | 142.973 | 52 | 46.682 | 4 | < .001 |
- 似然比检验显著,说明移除协变量回归路径会显著降低模型拟合。
- 因此,这两个协变量作为直接效应纳入模型有统计支持。
调节模型结果
| Model | AIC | BIC | χ² | df | χ² difference | df difference | p value |
|---|---|---|---|---|---|---|---|
| Moderation model with covariates free | 3791.8 | 3917.5 | 173.83 | 95 | |||
| Moderation model with covariates fixed | 3788.7 | 3907.8 | 174.69 | 97 | .856 | 2 | .65 |
- 调节模型中,交互效应固定和自由估计两个版本的拟合指标都可接受。
- 但释放交互效应并没有显著改善模型,p = .65。
- 因此,数据更支持协变量的直接效应,而不支持本文构造的交互效应。
- 作者提醒,不显著结果不能简单解释为“没有效应”,尤其是在样本量有限或交互效应较复杂时。
- 直接效应模型和调节模型不是嵌套模型,因为调节模型引入了新的交互潜变量,因此不能直接用似然比检验比较二者。
4. Concluding Remarks
本文结果总结
- 本文提供了使用 SEM forests 识别遗漏协变量的操作指南。
- 在示例中,SEM forests 从 8 个候选协变量中识别出两个有影响的协变量:
general interest in mathematicsuniversity-related interest in mathematics
- 将它们纳入模型后,模型拟合改善。
- 直接效应模型获得更明确的统计支持。
SEM forests 的流程总结
- 作者从原始数据中通过 subsampling 生成 2000 个训练数据集。
- 每个训练数据集都拟合到没有协变量的初始 SEM,即根模型。
- 在根模型基础上,SEM trees 根据协变量取值递归分裂数据。
- 每个节点既代表一个由协变量定义的数据划分,也对应一个在该子样本上估计的 SEM。
- 之后对每个协变量进行置换,并重新计算模型拟合。
- 如果置换某协变量后模型拟合下降更大,说明该协变量更重要。
与修正指数的区别
- 修正指数只能评估初始模型中已有变量之间的参数结构修改。
- 它不能直接指出哪个模型外观测变量应被纳入。
- 即便误差相关提示存在未建模方差,修正指数也无法说明具体遗漏了哪个变量。
- SEM forests 的优势在于可以识别初始模型外的有影响协变量。
使用 SEM forests 的注意事项
- SEM forests 的结果依赖数据准备,尤其是缺失值处理。
- 它也依赖树和森林的参数设置,例如抽样方法、分裂方法、
mtry、Bonferroni 校正、alpha、min.N、min.bucket和树数量。 - SEM forests 只能告诉研究者哪些协变量可能重要,不能自动决定这些协变量应放入模型的哪里。
- 偏依赖图可以帮助探索协变量对特定模型参数的影响,但对于类别很少的变量,解释价值有限。
过拟合与偶然性资本化
- 规格搜索通常是必要的,但模型修改必须有理论基础。
- 过多事后修改可能导致过拟合。
- 作者建议使用交叉验证、独立样本验证、分半验证或 bootstrap 检查模型稳定性。
- 只依赖经验结果会增加偶然性资本化风险;这种风险既存在于修正指数,也存在于 SEM forests。
Electronic Appendix
补充分析目的
- Electronic Appendix 说明如何在含缺失值的数据中进行 SEM forests 分析。
- 主文使用插补后的数据;附录使用未插补数据。
- 目的是检查缺失值处理是否会影响变量重要性排序和模型拟合结果。
score-guided tests 对缺失值的限制
- 主文使用 score-guided tests 生成 SEM trees。
- 该方法要求预测变量和模型变量中都没有缺失值。
- 如果数据中存在缺失值,SEM forest 会没有有效树,并出现错误:
Error in varimp(forest_dsreal) : No valid trees in the forest.
Error in varimp(forest_dsreal):错误发生在计算forest_dsreal的变量重要性时。No valid trees in the forest.:说明森林中没有有效树,因此无法计算变量重要性。
替代方法:naïve splitting method
- 附录改用 naïve splitting method。
- 作者提醒,该方法需要更多计算资源,统计功效也低于 score-guided tests。
- 因此,它只是含缺失值情境下的替代方案。
图 1:缺失值数据集的变量重要性
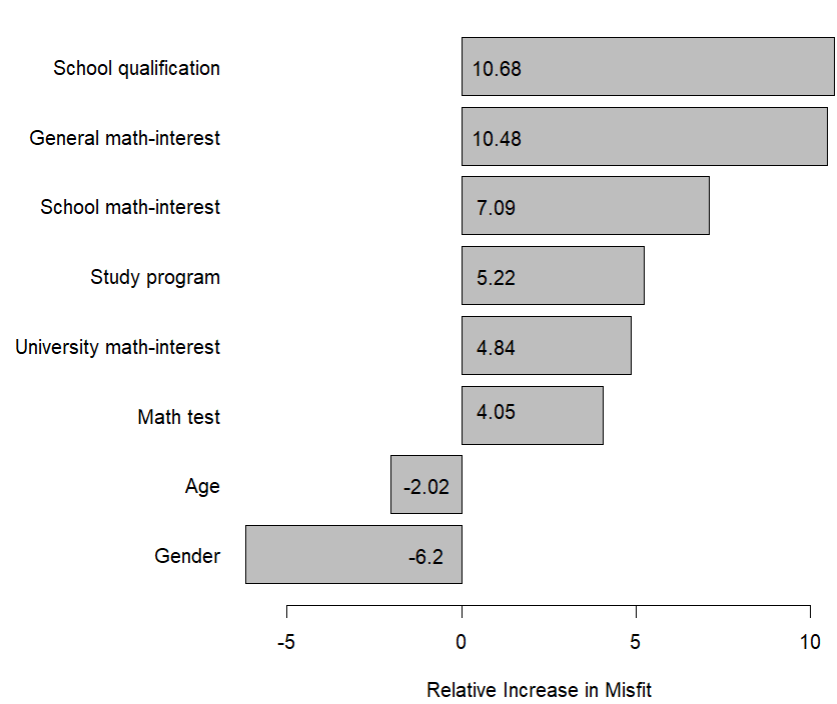
- 在未插补数据中,变量重要性最高的是
general school qualification,数值为 10.68。 - 第二是
general interest in mathematics,数值为 10.48。 - 第三是
school-related interest in mathematics,数值为 7.09。 age和gender为负值,不应视为稳定的重要协变量。- 与主文结果相比:
general interest in mathematics在两种分析中都被识别为有影响协变量;- 主文中的另一个有影响协变量是
university-related interest in mathematics; - 附录中则变为
general school qualification。
表 1:缺失值数据集的模型拟合
| Model | CFI | RMSEA | SRMR |
|---|---|---|---|
| Initial Model | .95 | .08 | .06 |
| Model with Covariate Direct Effects Fixed | .87 | .10 | .13 |
| Model with Covariate Direct Effects Free | .94 | .08 | .06 |
| Moderation Model with Covariates Fixed | .90 | .07 | .07 |
| Moderation Model with Covariates Free | .90 | .07 | .07 |
表 1 解释
- 直接效应自由估计模型优于直接效应固定模型:CFI 更高,RMSEA 和 SRMR 更低。
- 但初始模型的 CFI = .95,略高于直接效应自由估计模型的 .94;两者 RMSEA 和 SRMR 相同。
- 调节模型中,自由估计版本与固定版本拟合指标完全相同,说明释放交互效应没有改善模型。
- 与插补数据相比,直接效应自由估计模型的 CFI 和 SRMR 相同,但插补数据的 RMSEA 略好。
- 对调节模型而言,插补数据的拟合指标整体更好。
Electronic Appendix 结论
- 缺失值处理会影响 SEM forests 的变量重要性排序。
general interest in mathematics结果较稳定,因为它在插补数据和未插补数据中都被识别为有影响协变量。- 另一个重要协变量会随缺失值处理方式变化。
- 因此,实际研究应报告缺失值处理方式,并检查结果对缺失值处理的敏感性。
Appendix A
初始模型
initial_model <- "
sc_all1 =~ M1SAll1 + M1SAll2 + M1SAll3 + M1SAll4
sc_all2 =~ M2SAll1 + M2SAll2 + M2SAll3 + M2SAll4
m2_sw =~ M2SW1 + M2SW2
sc_all2 ~ a*sc_all1 # direct effect
m2_sw ~ b*sc_all2 + c*sc_all1
indirect := a*b
total := c + a*b
"
initial_model <- "...":把 lavaan 模型语法保存为initial_model。sc_all1 =~ M1SAll1 + M1SAll2 + M1SAll3 + M1SAll4:定义潜变量sc_all1,由四个 t1 指标测量。sc_all2 =~ M2SAll1 + M2SAll2 + M2SAll3 + M2SAll4:定义潜变量sc_all2,由四个 t2 指标测量。m2_sw =~ M2SW1 + M2SW2:定义潜变量m2_sw,对应tendency to change study program。sc_all2 ~ a*sc_all1:设置sc_all1对sc_all2的回归路径,并将系数命名为a。m2_sw ~ b*sc_all2 + c*sc_all1:设置sc_all2和sc_all1对m2_sw的回归路径,系数分别命名为b和c。indirect := a*b:定义间接效应。total := c + a*b:定义总效应。
协变量效应固定为 0 的模型
model_cov_fixed <- "
sc_all1 =~ M1SAll1 + M1SAll2 + M1SAll3 + M1SAll4
sc_all2 =~ M2SAll1 + M2SAll2 + M2SAll3 + M2SAll4
m2_sw =~ M2SW1 + M2SW2
sc_all1 ~ 0*in_hs1 + 0*in_all1
sc_all2 ~ a*sc_all1 # direct effect
m2_sw ~ b*sc_all2 + c*sc_all1 + 0*in_hs1 + 0*in_all1
indirect := a*b
total := c + a*b
"
- 前三行仍然是测量模型。
sc_all1 ~ 0*in_hs1 + 0*in_all1:把in_hs1和in_all1对sc_all1的路径固定为 0。m2_sw ~ ... + 0*in_hs1 + 0*in_all1:把两个协变量对m2_sw的路径固定为 0。- 该模型用于作为限制模型,与自由估计模型比较。
协变量效应自由估计的模型
model_cov_free <- "
sc_all1 =~ M1SAll1 + M1SAll2 + M1SAll3 + M1SAll4
sc_all2 =~ M2SAll1 + M2SAll2 + M2SAll3 + M2SAll4
m2_sw =~ M2SW1 + M2SW2
sc_all1 ~ NA*in_hs1 + NA*in_all1
sc_all2 ~ a*sc_all1 # direct effect
m2_sw ~ b*sc_all2 + c*sc_all1 + NA*in_hs1 + NA*in_all1
indirect := a*b
total := c + a*b
"
NA*in_hs1和NA*in_all1表示对应路径由 lavaan 自由估计。- 该模型检验两个协变量作为直接效应是否能改善模型拟合。
调节模型:交互效应固定为 0
moderation_model_fixed <- "
int1 =~ in_hs1.M1SAll4 + in_all1.M1SAll4
int2 =~ in_hs1.M2SW2 + in_all1.M2SW2
sc_all1 =~ M1SAll1 + M1SAll2 + M1SAll3 + M1SAll4
sc_all2 =~ M2SAll1 + M2SAll2 + M2SAll3 + M2SAll4
m2_sw =~ M2SW1 + M2SW2
sc_all1 ~ NA*in_hs1 + NA*in_all1 + 0*int1
sc_all2 ~ a*sc_all1 # direct effect
m2_sw ~ b*sc_all2 + c*sc_all1 + NA*in_hs1 + NA*in_all1 + 0*int2
indirect := a*b
total := c + a*b
"
int1 =~ ...:定义交互潜变量int1。int2 =~ ...:定义交互潜变量int2。0*int1和0*int2:将交互效应固定为 0。- 该模型作为调节模型的限制版本。
调节模型:交互效应自由估计
moderation_model <- "
int1 =~ in_hs1.M1SAll4 + in_all1.M1SAll4
int2 =~ in_hs1.M2SW2 + in_all1.M2SW2
sc_all1 =~ M1SAll1 + M1SAll2 + M1SAll3 + M1SAll4
sc_all2 =~ M2SAll1 + M2SAll2 + M2SAll3 + M2SAll4
m2_sw =~ M2SW1 + M2SW2
sc_all1 ~ NA*in_hs1 + NA*in_all1 + NA*int1
sc_all2 ~ a*sc_all1 # direct effect
m2_sw ~ b*sc_all2 + c*sc_all1 + NA*in_hs1 + NA*in_all1 + NA*int2
indirect := a*b
total := c + a*b
"
NA*int1:自由估计int1对sc_all1的交互效应。NA*int2:自由估计int2对m2_sw的交互效应。- 该模型用于检验交互效应是否在直接效应之外进一步改善模型拟合。
参考文献
Arnold, M., Voelkle, M. C., & Brandmaier, A. M. (2021). Score-guided structural equation model trees. Frontiers in Psychology, 11, Article 564403. https://doi.org/10.3389/fpsyg.2020.564403
Brandmaier, A. M., Prindle, J. J., McArdle, J. J., & Lindenberger, U. (2016). Theory-guided exploration with structural equation model forests. Psychological Methods, 21(4), 566–582. https://doi.org/10.1037/met0000090
Brandmaier, A. M., von Oertzen, T., McArdle, J. J., & Lindenberger, U. (2013). Structural equation model trees. Psychological Methods, 18(1), 71–86. https://doi.org/10.1037/a0030001
Browne, M. W., & Cudeck, R. (1993). Alternative ways of assessing model fit. In K. A. Bollen & J. S. Long (Eds.), Testing structural equation models (pp. 136–162). Sage.
Hu, L.-t., & Bentler, P. M. (1999). Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Structural Equation Modeling: A Multidisciplinary Journal, 6(1), 1–55. https://doi.org/10.1080/10705519909540118
Kline, R. B. (2023). Principles and practice of structural equation modeling (5th ed.). Guilford Press.
Rosseel, Y. (2012). lavaan: An R package for structural equation modeling. Journal of Statistical Software, 48(2), 1–36. https://doi.org/10.18637/jss.v048.i02
Silva Díaz, J. A., Heene, M., & Ufer, S. (2026). A practical guide to using SEM forests for specification search in structural equation modeling. Structural Equation Modeling: A Multidisciplinary Journal, 33(1), 145–156. https://doi.org/10.1080/10705511.2025.2526028
Strobl, C., Malley, J., & Tutz, G. (2009). An introduction to recursive partitioning: Rationale, application, and characteristics of classification and regression trees, bagging, and random forests. Psychological Methods, 14(4), 323–348. https://doi.org/10.1037/a0016973